Removing VMFS stale locks
I recently had to try to recover a VMWare cluster, that had experienced a power outage.
When the ESXi hosts came back up, most of the VMs appeared in an Invalid / Unknown state, including the vCenter:

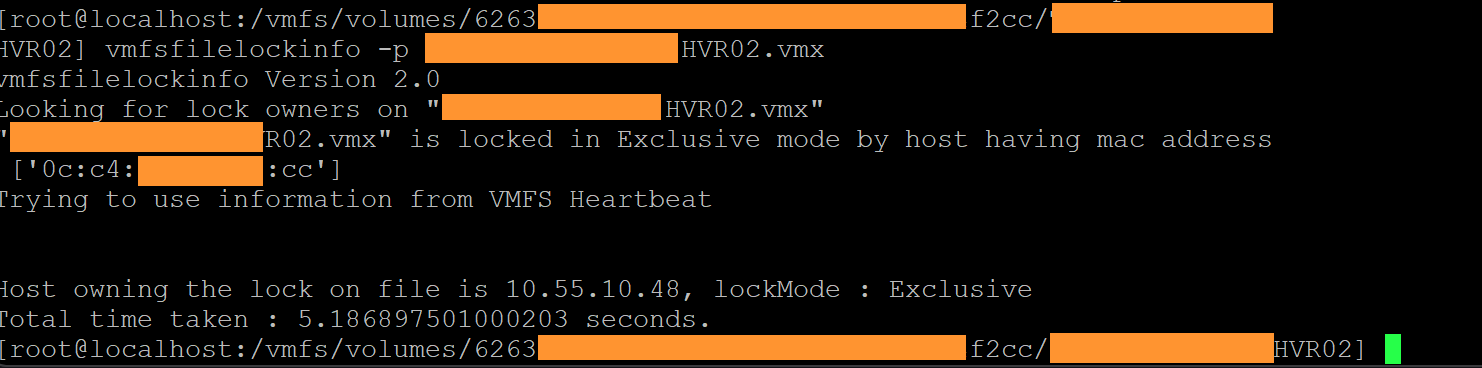
Trying to unregister and reregister the VMs didn't work. Jumping into the SSH console, and using vmfsfilelockinfo, I could see that the VMX and VMDK files were locked by the hypervisor that I was using. There was a stale lock, that wasn't released after the hypervisor rebooted.
The VMs were definately offline, and the obvious things--putting the host into Maintanance Mode, trying to rm the lock files, didn't work.

Reading various VMWare Communities threads and blog posts, I realised I had to:
- unmount the datastore
- use the VOMA tool to clear the stale locks
- remount the datastore
- hope the VMs themselves were ok (spoiler alert: many had filesystem errors in the guests as well... but that was a secondary concern)
The first task was straightforward - one by one, I went and unregistered the VMs from the hypervisor.
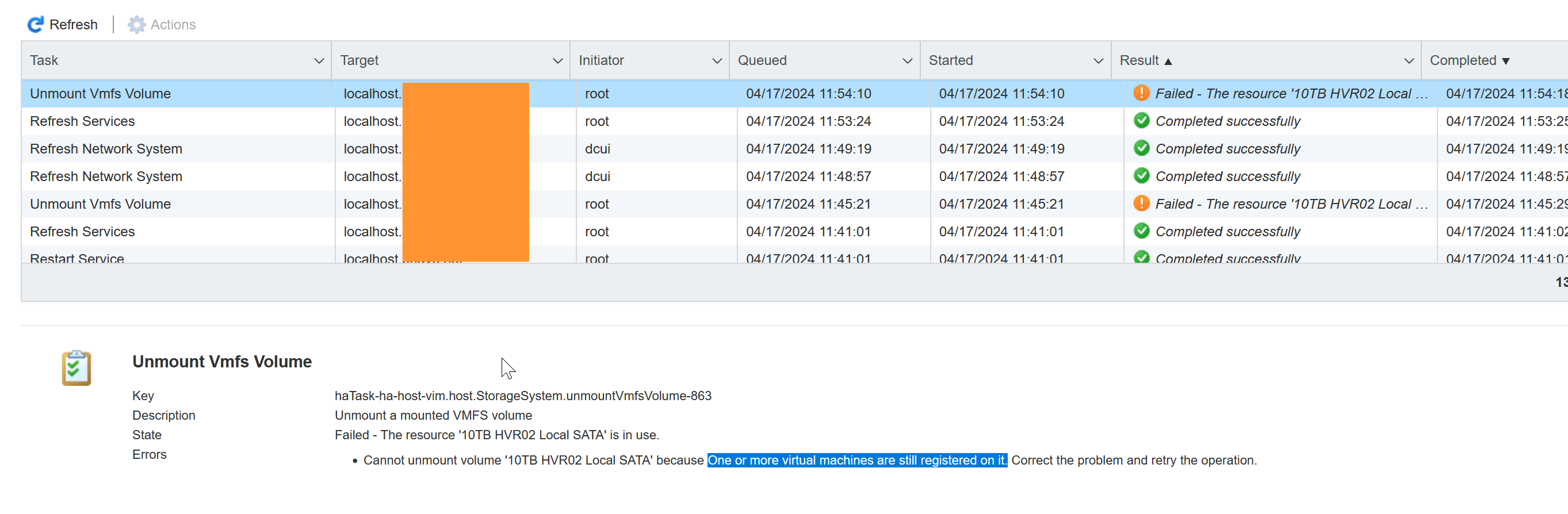
But, after doing that, something still prevented the datastore from being unmounted, with a super-helpful error that "file system is busy".
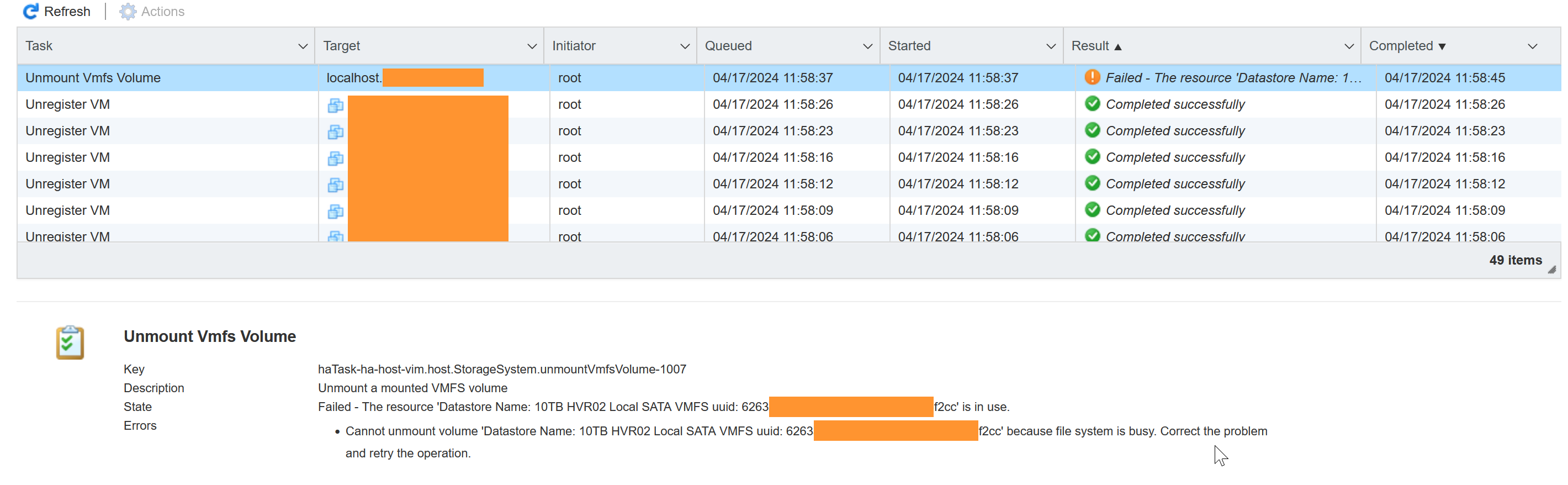
Going back to SSH, using lsof I could see that the vdtc process still had a file open in a .locker directory on the datastore.
After trying to figure out what vdtc was, it took me a minute to remember that ESXi uses a scratch location on the datastore to store log and temp files, so that it doesn't quickly wear out SD cards. vdtc is the vSphere Distrubuted Tracing Collector.
I was able to:
- Confirm this with
vim-cmd hostsvc/advopt/view ScratchConfig.ConfiguredScratchLocation, and make a note of the current location - Set the scratch location to the Bootbank backup partition with
vim-cmd hostsvc/advopt/update ScratchConfig.ConfiguredScratchLocation string/vmfs/volumes/BOOTBANK2/.locker-temp - As it didn't look like I could restart the
vdtcservice directly, reboot the hypervisor.
Note: Do not leave the hypervisor with a scratch on a SD card. Your repaired cluster will break again, and quickly.



Finally, I was able to unmount the datastore!
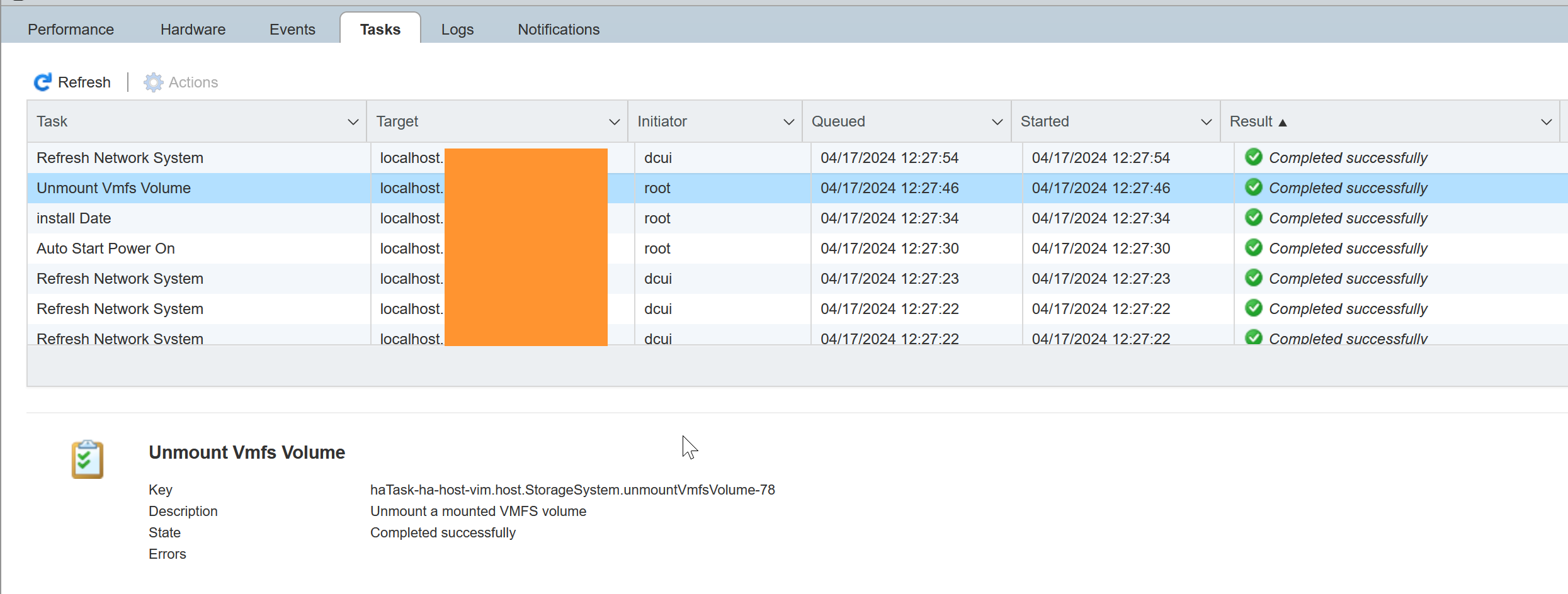
Running VOMA on the disk, and using -s to write the output to a log file, I was able to see that apart from the stale locks, VOMA didn't report any other issues with the VMFS.
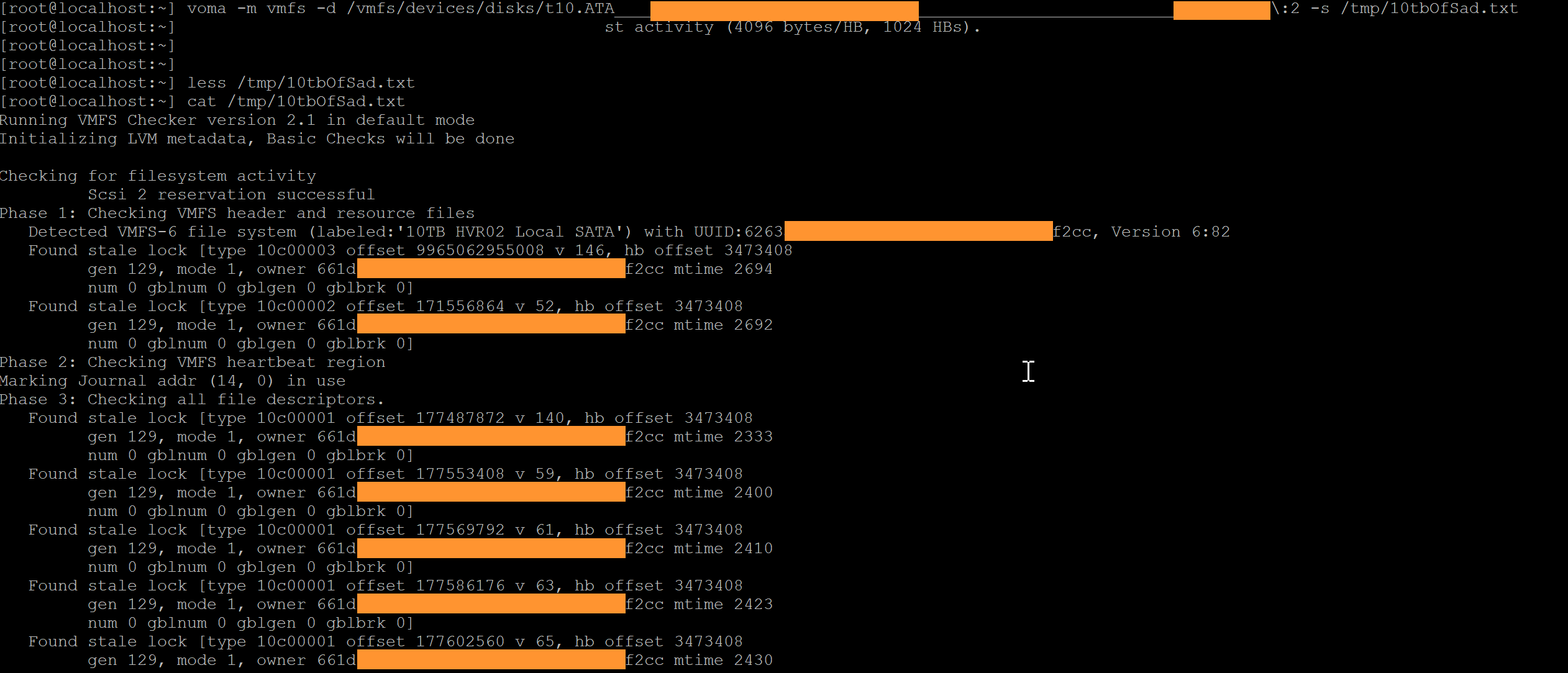
I then ran the same VOMA command again, with -f fix. The log output looked positive, so I then remounted the datastore, re-registered the VMs, and... it worked!
After remounting the datastore, I saw the locks were gone, and was able to re-register the VMs.
